WPL 语言基础
本文档介绍 wp-lang 中的 WPL 规则语言基础元素与常用写法,内容与当前解析实现保持一致。
WPL 用于定义“规则(rule)”,每条规则由一个或多个“分组(group)”构成,分组内包含若干“字段(field)”抽取项。
提示:完整的形式化语法见《WPL 语法(EBNF)》:./06-grammar-reference.md。
最小示例
package net {
rule nginx_access {
(
digit:status,
time_3339:recv_time,
ip:client_ip,
http/request,
http/agent"
)
}
}
基本结构
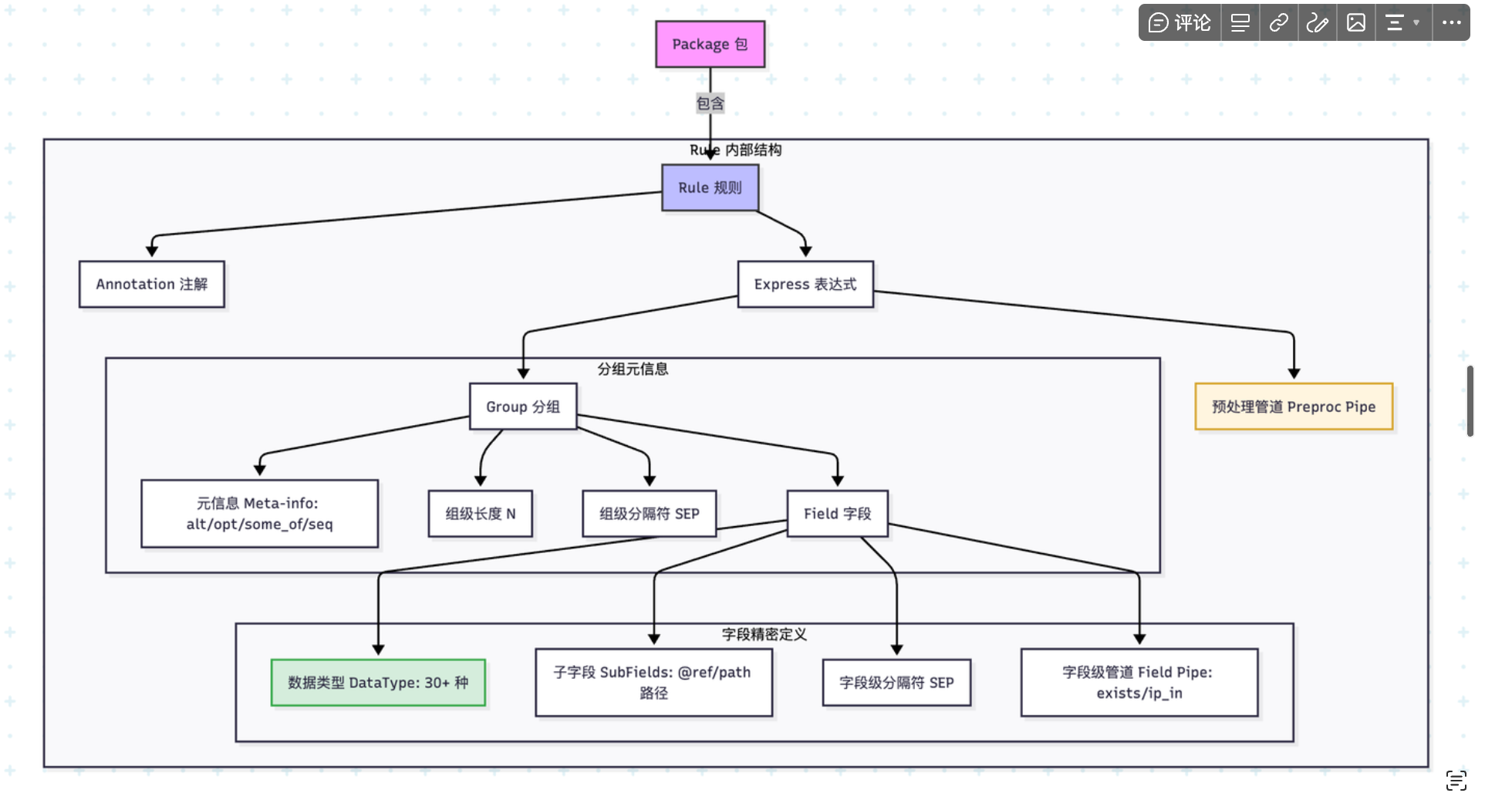
- package:包名作为作用域;一个包内包含多条 rule
- rule:规则名可包含路径分隔符(
/a/b), - 表达式(Express):可含“预处理管道”与一个或多个“分组”
package demo {
# 可选:标签/复制原文注解可加在 package 或 rule 上,编译时会合并
#[tag(sys:"ids"), copy_raw(name:"raw_payload")]
rule /service/http {
|decode/base64|unquote/unescape| # 预处理(可选)
(
ip:src_ip, # 基本字段
ip:dst_ip,
time:occur_time,
5*_, # 连续占位字段(忽略)
http/request<[,]>, # 范围定界格式 <beg,end>
http/agent"
)
}
}
分组(Group)
- 形式:
(<fields>)[N][SEP] - 元信息(可选):
alt | opt | some_of | seq - 长度
[N]会应用到组内所有字段(等价于每个字段后[N]) - 分隔符
SEP写法为逐字符反斜杠转义:如\,表示,,\!\|表示!|
示例:
seq(ip:sip,2*_,time:recv_time<[,]>,http/request:req",http/status:status,digit:bytes,chars:referer",http/agent:ua",chars:xff")
尾随逗号规则(两者均允许):
- 分组字段列表允许尾随逗号;
- 子字段列表允许尾随逗号。
# 正确:分组允许尾随逗号
rule ok_group { (ip, digit,) }
# 正确:子字段允许尾随逗号
rule ok_subfields { (kv(ip@src, digit@port,)) }
分组元信息语义(alt/opt/some_of/seq)
- seq(默认):按声明顺序依次匹配每个字段;任一字段失败导致整个分组失败。连续字段(如
3*ip)会在该位置多次尝试直到次数耗尽或失败。 - alt(择一):按顺序尝试分组内各字段,只要有一个字段成功就停止;若全部失败则分组失败。常用于“同位不同类型”的容错匹配,如
alt(ip,digit)。 - some_of(尽可能多):在当前位置反复尝试匹配“任一字段”,每次循环最多消费一个字段;直到一次循环中所有字段都失败为止(此时停止且不报错)。常用于扫描“零散重复”的键值、片段等。
- opt(可选):仅尝试匹配分组内的第一个字段,一次机会;失败不报错,继续后续分组。建议在
opt(...)内仅写一个字段,额外字段将被忽略。
示例
# seq:全部匹配且按顺序
rule g_seq { (ip, time_3339) }
# alt:择一匹配
rule g_alt { alt(ip, digit) }
# some_of:尽可能多地匹配(每轮最多消费一个)
rule g_some_of { some_of(ip, digit) }
# opt:可选(建议仅一个字段)
rule g_opt { opt(ip) }
注意
- 分组级
[..](长度)与分隔符会注入到分组内字段(作为默认值)并结合字段自身格式解析。 some_of与alt在嵌套到kv/json等复合类型时的具体行为,依赖协议解析器实现;常见用法是在键值对中匹配“候选值之一”或“尽可能多的候选值”。
字段(Field)
通用形态(按顺序可选):
[N*] DataType [ (symbol 内容) ] [ (子字段列表) ] [:name] [ [len] ] [ 格式 ] [ 分隔符 ] { | 管道 }
- 重复计数:
*ip或3*ip表示连续匹配项(_为忽略占位) - 数据类型:与
wp-data-model::DataType对应,例如:digit/time_3339/ip/kv/json/http/request等 - symbol 内容:仅
symbol/peek_symbol可带,如symbol(boy) - 子字段:用于
kv/json/array/obj等复合类型,形如(digit@message_type, time@access_time) - 命名:
:name指定抽取后的目标字段名 - 长度:
[N]限定最大长度 - 格式:
- 范围定界:
<beg,end>,如<[,]> - 引号:
"(等价首尾均为") - 计数字段:
^N(仅对chars/_合法)
- 范围定界:
- 分隔符:使用反斜杠转义逐字符拼接,如
\\,、\\!\\| - 字段级管道:
| exists(src)或| (time,ip)(可嵌套一个分组作为管道)
示例:
(
ip:sip, # 命名字段
_^2, # 两个忽略位(以计数方式)
time<[,]>, # 范围定界格式
http/request",
digit[10]\\, # 含长度与分隔符
json(chars@key | exists(src)) # 子字段 + 函数管道
)
子字段(SubFields)
- 形态:
( <sub_field> [, <sub_field>]* ) - 子字段写法与普通字段一致,额外支持
opt(DataType)标注为可选 - 子字段键:默认键为
*(通配);显式使用@ref/path指定键
示例:
kv(
time@access_time,
ip@sip,
opt(digit)@dns_type
)
预处理管道(表达式级)
写在表达式起始处:|decode/base64|unquote/unescape|。与字段级 | ... 管道不同,预处理作用域为整条规则的输入原文。
用途与执行时机
- 作用域:在解析字段前,对整行原始输入进行一次或多次顺序转换;转换后的文本再进入分组/字段解析。
- 执行顺序:自左向右;每个步骤的输出作为下一个步骤的输入。
- 失败处理:任一步骤失败即报错;未知步骤名会在装配阶段报
UnSupport(<name>)。
语法与可用步骤
- 语法:
'|' ws? preproc_step { ws? '|' ws? preproc_step } ws? '|'(必须以|结尾,支持空白)。 preproc_step支持两类:- 内置步骤:与旧语法一致,token 需满足
take_key规则(字母、数字、_、/、-、.等)。 - 自定义扩展:写成
plg_pipe/<name>,解析器会在预处理注册表中按名称查找实现。
- 内置步骤:与旧语法一致,token 需满足
- 内置步骤(唯一支持的命名空间写法,实现在
eval/builtins):decode/base64:对整行进行 Base64 解码;失败报错。unquote/unescape:移除外层引号并还原文本中的反斜杠转义(常用于还原日志中的\"为")。decode/hex:按十六进制文本进行解码(如48656c6c6f→Hello)。
- 自定义
plg_pipe/<name>:通过代码调用register_wpl_pipe!("NAME", builder)注册,builder返回实现PipeProcessor的处理器。
示例
# 1) 先 Base64,再解压/还原引号(示例步骤名 zip 仅作演示,非内置)
rule r1 {
|decode/base64|unquote/unescape|
(json(chars@payload))
}
# 2) 仅进行十六进制解码
rule r2 {
|decode/hex|
(chars:raw)
}
常见问题与提示
- 预处理步骤名必须以
|收尾,否则会产生语法错误(实现强校验)。 - 仅有
plg_pipe/<name>可以挂载外部扩展,注册接口位于wpl::register_wpl_pipe!(编译期直接调用)。 - 预处理只影响“整行输入”,不会对字段子串单独生效;字段层面的转换请使用字段级
| fun(...)管道。
字段级函数(管道)
内置函数(与解析实现一致):
exists(name)exists_chars(name, path)/chars_not_exists(name, path)/exists_chars_in(name, [path,...])exists_digit(name, N)/exists_digit_in(name, [N,...])exists_ip_in(name, [1.1.1.1, 2.2.2.2])str_mode("raw mode string")
示例:
(json(chars@name, chars@code) | chars_not_exists(name, a/b/c))
注解(Annotation)
支持添加在 package 或 rule 前,编译时会合并到 rule:
#[tag(t1:"id",t2:"sn"), copy_raw(name:"raw")]
package test {
#[tag(t3:"sub")]
rule x { (digit,time) }
}
注解值支持通用引号字符串(可包含空格、中文与转义):
#[tag(desc:"中文 标记", note:"say \"hi\"")]
package demo { rule x { (digit) } }
也可以使用原始字符串,减少转义负担(不处理反斜杠转义):
#[tag(path:r#"C:\\Program Files\\App"#, note:r#"a\b\c \"quote\""#)]
package demo { rule x { (digit) } }
插件(Plugin)
使用“代码块内联”形式,不需要转义:
rule test_plugin {
plg_pipe(id: dayu) {
(json(_@_origin,_@payload/packet_data))
}
}
常用数据类型(节选)
- 基础:
boolcharsdigitfloat_sn - 时间:
timetime_isotime_3339time_2822time_timestamp - 网络:
ipip_netdomainemailport - 文本/协议:
hexbase64kvkvarrjsonexact_jsonhttp/requesthttp/statushttp/agenthttp/methodurl - 结构:
objarray[/subtype]symbolpeek_symbol
更多产生式请参考《WPL 语法(EBNF)》:./02-wpl_grammar.md。
Array 类型
- 语法:
array[/subtype](如:array/digit、array/chars、array/array/digit);不写 subtype 时默认为auto。 - 作用:解析中括号数组文本(如
[1,2,3]),按元素展开为独立字段,路径命名为<name>/[index]。 - 元素规则:
- 分隔:逗号
,;允许尾随逗号([1,2,3,]合法)。 - 结束:右括号
];支持空数组[]。 - 字符串元素使用引号包裹,内部逗号不会被误分隔(优先按引号解析)。
- 分隔:逗号
- 示例:
rule arr { (array/digit:nums) } # "[1,2,3,]" -> nums/[0]=1, nums/[1]=2, nums/[2]=3 rule arr2 { (array/chars:items) } # "[\"hello\", \"_F]fe\", \"!@#$*&^\\\"123\"]" -> items/[0]="hello", items/[1]="_F]fe", items/[2]="!@#$*&^\"123"
KvArr 类型(键值对数组)
- 语法:
kvarr(subfield1, subfield2, ...) - 作用:解析
key=value或key:value格式的键值对数组,支持逗号或空格分隔。 - 支持格式:
- 逗号分隔:
a="foo", b=bar, c=123 - 空格分隔:
a="foo" b=bar c=123 - 混合分隔:
a="foo", b=bar c=123 - 键值分隔符:支持
=或:(如a=1或a:1)
- 逗号分隔:
- 值类型支持:
- 字符串:带引号或不带引号(如
"value"或value) - 数字:整数和浮点数(如
123或1.25) - 布尔值:
true或false(不区分大小写) - 自动类型推断:根据值的格式自动判断类型
- 字符串:带引号或不带引号(如
- 重复键处理:
- 当同一个键出现多次时,会自动添加数组索引
- 例如:
tag=alpha tag=beta tag=gamma→tag[0]="alpha",tag[1]="beta",tag[2]="gamma"
- 子字段配置:
- 支持在括号内定义子字段的类型和名称映射
- 支持元字段(
_@name)来忽略特定键 - 支持嵌套解析器(通过子字段配置触发)
- 示例:
# 基本用法 rule parse_kvarr { (kvarr(ip@sip, digit@cnt)) } # 输入:"sip=192.168.1.1, cnt=42" # 输出:sip=192.168.1.1 (ip类型), cnt=42 (digit类型) # 空格分隔 rule parse_whitespace { (kvarr(chars@a, chars@b, digit@c)) } # 输入:"a=\"foo\" b=bar c=1" # 输出:a="foo", b="bar", c=1 # 重复键自动索引 rule parse_repeated { (kvarr(chars@tag)) } # 输入:"tag=alpha tag=beta tag=gamma" # 输出:tag[0]="alpha", tag[1]="beta", tag[2]="gamma" # 类型自动推断 rule parse_types { (kvarr(bool@flag, float@ratio, chars@raw)) } # 输入:"flag=true ratio=1.25 raw=value" # 输出:flag=true (bool), ratio=1.25 (float), raw="value" (chars) # 忽略元字段 rule parse_with_meta { (kvarr(_@note, digit@count)) } # 输入:"note=something count=7" # 输出:note (ignored), count=7
分隔符优先级与合并(sep)
- 来源与写法:
- 字段级:在字段末尾用反斜杠转义指定,如
digit\,、chars\!\|(优先级 3,覆盖)。 - 组级:在分组右括号后指定,如
(ip, digit)\,(优先级 2,默认)。 - 上游继承:来自外层上下文(如 kv/json/array/管道等)或默认空格(优先级 1,继承)。
- 字段级:在字段末尾用反斜杠转义指定,如
- 合并规则(combo):
- 字段级(3) 覆盖 组级(2) 覆盖 上游(1);否则继承上游。
- 特殊值:
\s表示空格;\0或0表示读到行尾。 - 打印规则:sep 标记默认会打印为反斜杠转义形式;某些“推断 sep”不会在格式化输出中重复打印(实现层“推断”)。
示例:
# 1) 组分隔符应用于组内:
rule g1 { (chars:a, chars:b)\| }
# 输入:"foo|bar" => a = foo, b = bar
# 2) 字段分隔符高于组分隔符:
rule g2 { (chars:a, chars:b\|)\, }
# 输入:"x,y|z" => a = x(用组分隔符 ,), b = y(用字段分隔符 |)
# 3) 读到行尾(\0):
rule g3 { (kv, chars\0) }
# 第二个字段捕获到行尾;常见于最后一个字段吸收余量